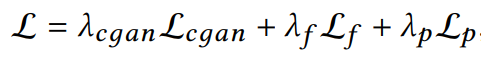Cheng P, Hao W, Dai S, et al. Club: A contrastive log-ratio upper bound of mutual information[C]//International conference on machine learning. PMLR, 2020: 1779-1788.
Poole B, Ozair S, Van Den Oord A, et al. On variational bounds of mutual information[C]//International Conference on Machine Learning. PMLR, 2019: 5171-5180.
# 传统bpr class BPRLoss(nn.Module): def __init__(self): super(BPRLoss, self).__init__()
def forward(self, logit): """ Args: logit (BxB): Variable that stores the logits for the items in the mini-batch The first dimension corresponds to the batches, and the second dimension corresponds to sampled number of items to evaluate B,N """ # differences between the item scores diff = logit.diag().view(-1, 1).expand_as(logit) - logit # final loss loss = -torch.mean(F.logsigmoid(diff)) return loss
class BPR_max(nn.Module): def __init__(self): super(BPR_max, self).__init__() def forward(self, logit): # 通过softmax表示sj logit_softmax = F.softmax(logit, dim=1) diff = logit.diag().view(-1, 1).expand_as(logit) - logit loss = -torch.log(torch.mean(logit_softmax * torch.sigmoid(diff))) return loss # top1loss
class TOP1Loss(nn.Module): def __init__(self): super(TOP1Loss, self).__init__() def forward(self, logit): """ Args: logit (BxB): Variable that stores the logits for the items in the mini-batch The first dimension corresponds to the batches, and the second dimension corresponds to sampled number of items to evaluate """ diff = -(logit.diag().view(-1, 1).expand_as(logit) - logit) loss = torch.sigmoid(diff).mean() + torch.sigmoid(logit ** 2).mean() return loss
class TOP1_max(nn.Module): def __init__(self): super(TOP1_max, self).__init__()
Global 表示在生成树之前进行候选切分点(candidate splits)的计算,且在整个计算过程中只做一次操作。在以后的节点划分时都使用已经提前计算好的候选切分点;Local 则是在每次节点划分时才进行候选切分点的计算。Global 适合在取大量切分点下使用; Local 更适用于深度较大的树结构。
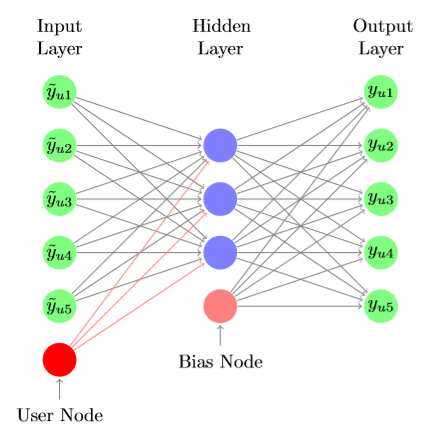
回顾《A Survey on Neural Recommendation: From Collaborative Filtering to Information-rich Recommendation》中,fashion recommendation是对Image information建模的代表任务,其目的在于增强可解释性。
DeepStyle: Learning User Preferences for Visual Recommendation(SIGIR 2017)
\(\operatorname*{min}_{\phi,\theta}{\cal L}_{r e c}=\operatorname*{min}_{\bigl|n\bigr|}\sum_{i=1}^{n}\left|\left|\,x_{i}-g_{\theta}(f_{\phi}(x_{i})\right\gt \right|^{2}\)
classMultiVAE(nn.Module): """ Container module for Multi-VAE. Multi-VAE : Variational Autoencoder with Multinomial Likelihood See Variational Autoencoders for Collaborative Filtering https://arxiv.org/abs/1802.05814 """
def__init__(self, p_dims, q_dims=None, dropout=0.5): # p_dims = [200, 600, n_items] super(MultiVAE, self).__init__() # q -> encoder | p-> decoder self.p_dims = p_dims # 确定维度 if q_dims: assert q_dims[0] == p_dims[-1], "In and Out dimensions must equal to each other" assert q_dims[-1] == p_dims[0], "Latent dimension for p- and q- network mismatches." self.q_dims = q_dims else: self.q_dims = p_dims[::-1] # [n_items, 600, 200]
# Last dimension of q- network is for mean and variance temp_q_dims = self.q_dims[:-1] + [self.q_dims[-1] * 2] # [ n_items, 600, 400] ] # encoder # in:[ n_items, 600] # out:[600, 400] self.q_layers = nn.ModuleList([nn.Linear(d_in, d_out) for d_in, d_out inzip(temp_q_dims[:-1], temp_q_dims[1:])]) # decoder # in:[200, 600,] # out:[600, n_items] self.p_layers = nn.ModuleList([nn.Linear(d_in, d_out) for d_in, d_out inzip(self.p_dims[:-1], self.p_dims[1:])]) self.drop = nn.Dropout(dropout) self.init_weights() defforward(self, input): mu, logvar = self.encode(input) z = self.reparameterize(mu, logvar) return self.decode(z), mu, logvar defencode(self, input): h = F.normalize(input) h = self.drop(h) for i, layer inenumerate(self.q_layers): h = layer(h) if i != len(self.q_layers) - 1: h = F.tanh(h) else: # 最后一层分均值和方差 mu = h[:, :self.q_dims[-1]] logvar = h[:, self.q_dims[-1]:] return mu, logvar
defreparameterize(self, mu, logvar): # 重参数化技巧 if self.training: std = torch.exp(0.5 * logvar) eps = torch.randn_like(std) return eps.mul(std).add_(mu) else: return mu defdecode(self, z): # 解码 h = z for i, layer inenumerate(self.p_layers): h = layer(h) if i != len(self.p_layers) - 1: h = F.tanh(h) return h
definit_weights(self): for layer in self.q_layers: # Xavier Initialization for weights size = layer.weight.size() fan_out = size[0] fan_in = size[1] std = np.sqrt(2.0/(fan_in + fan_out)) layer.weight.data.normal_(0.0, std)
# Normal Initialization for Biases layer.bias.data.normal_(0.0, 0.001) for layer in self.p_layers: # Xavier Initialization for weights size = layer.weight.size() fan_out = size[0] fan_in = size[1] std = np.sqrt(2.0/(fan_in + fan_out)) layer.weight.data.normal_(0.0, std)
# Normal Initialization for Biases layer.bias.data.normal_(0.0, 0.001)
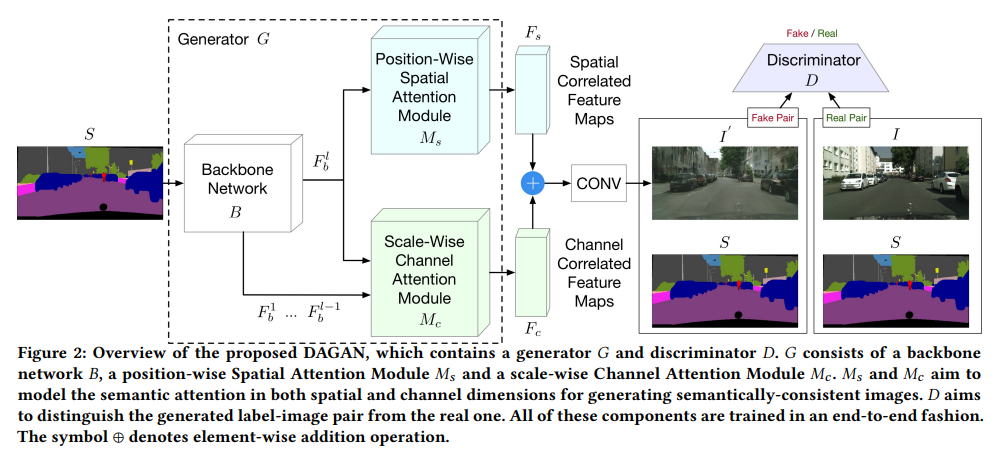
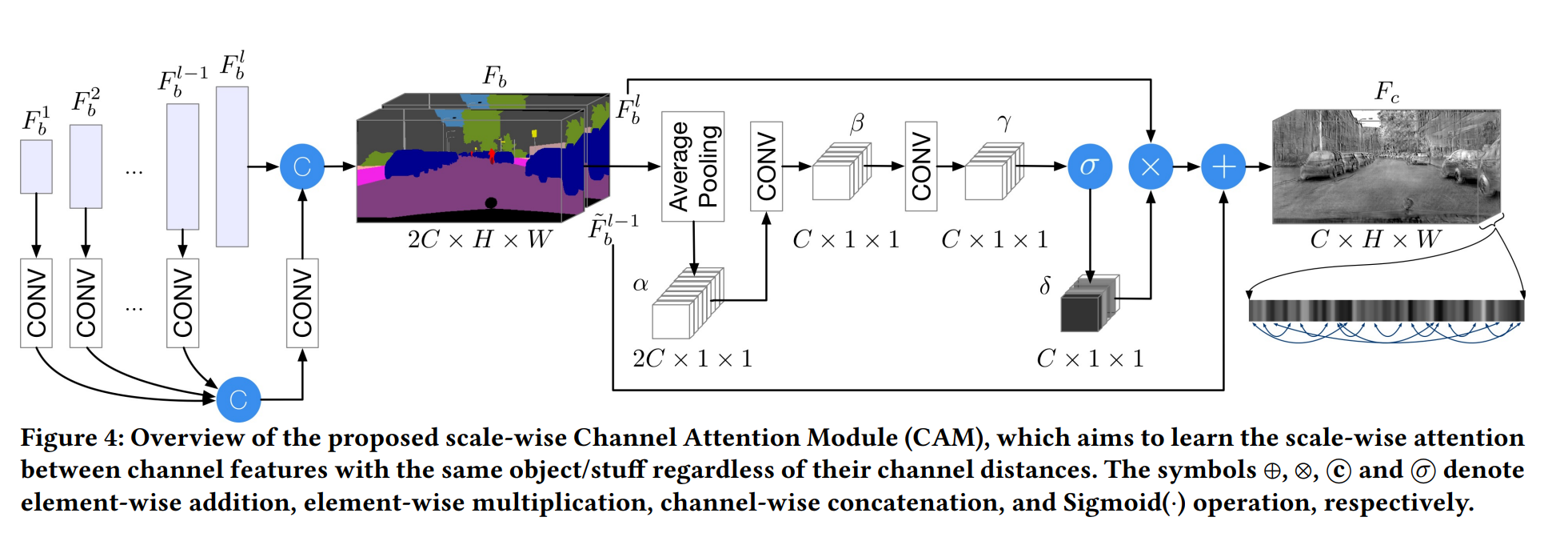
对于同样的objects,不同尺度的特征应该有联系。因此CAM将backbone中不同特征图做channel wised attention,有利于捕获这样的信息。实现中作者只用了上采样过程中的一个特征图(倒数第二个加conv),和输出做channel-wised concatnation(所以是2C x H x W)。Fb通过AdaptiveAvgPool再经过两个卷积层得到Cx1x1的


























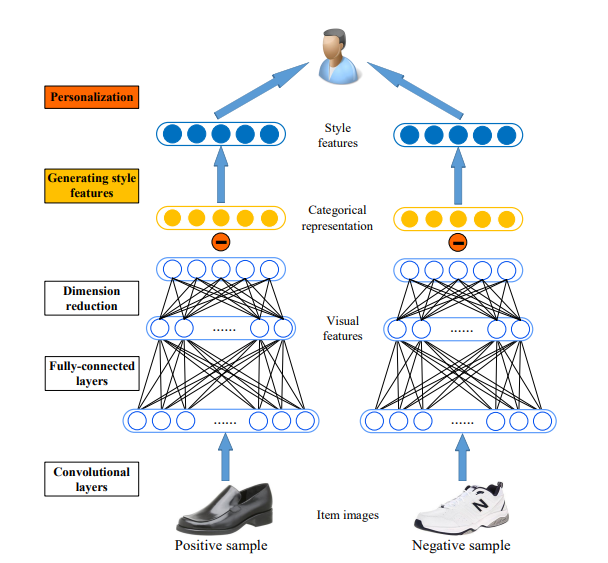
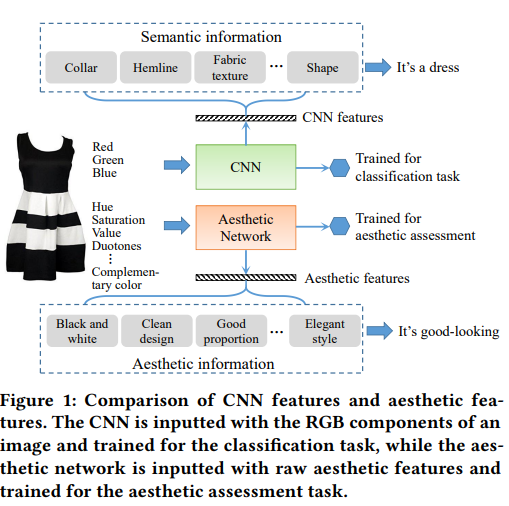
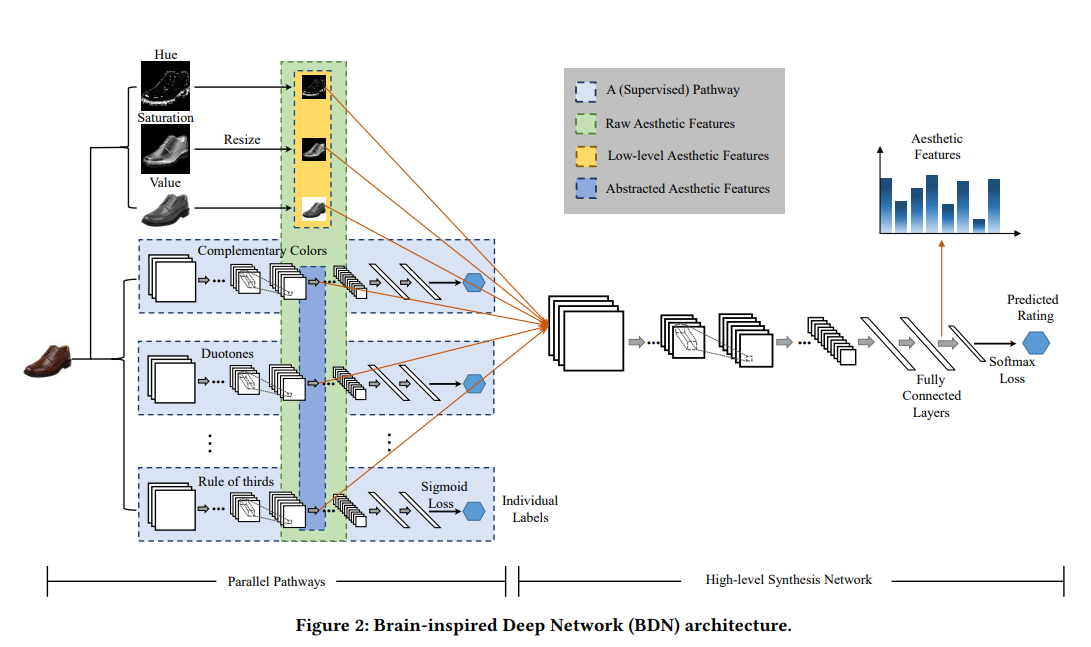
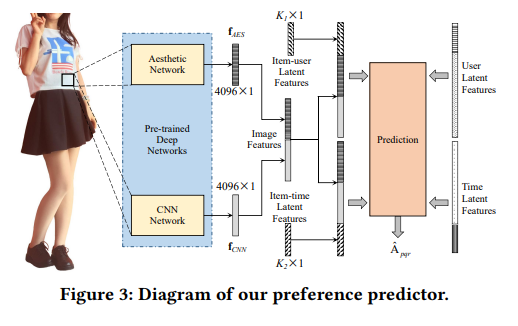

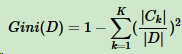
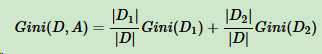
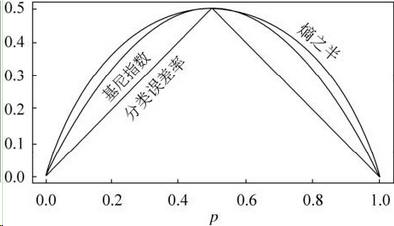
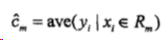
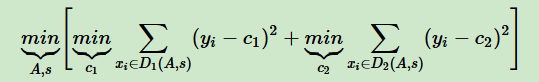



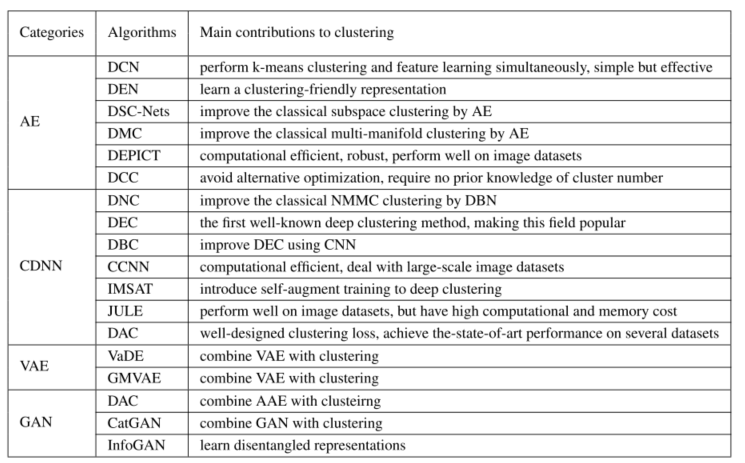
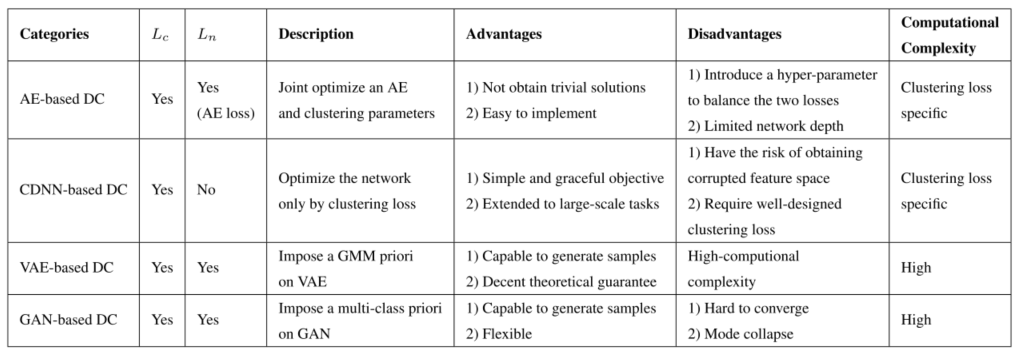
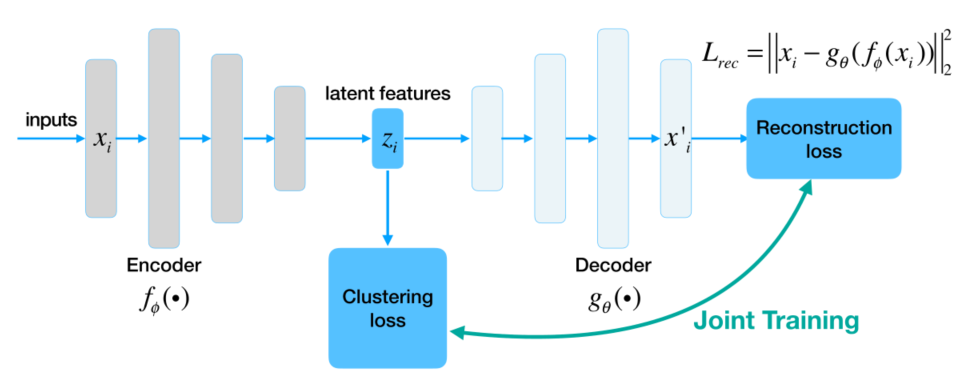
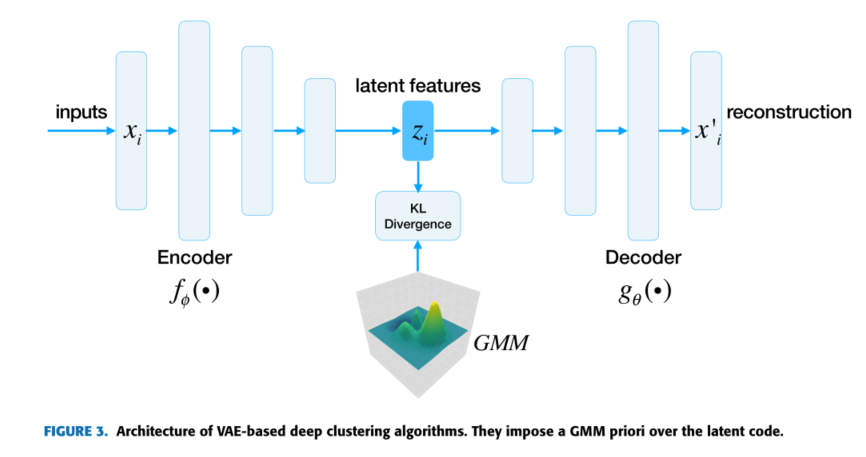



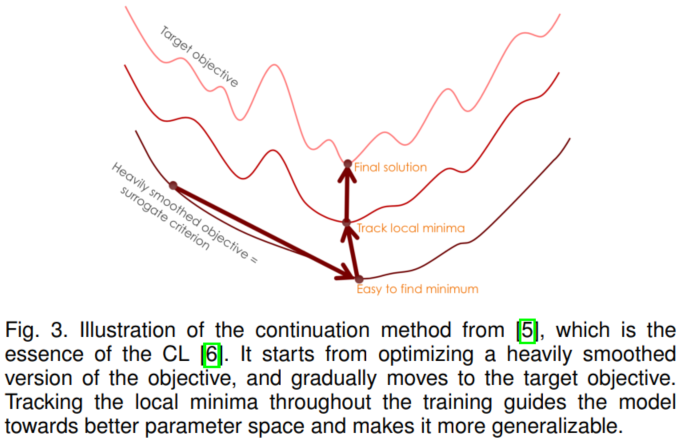
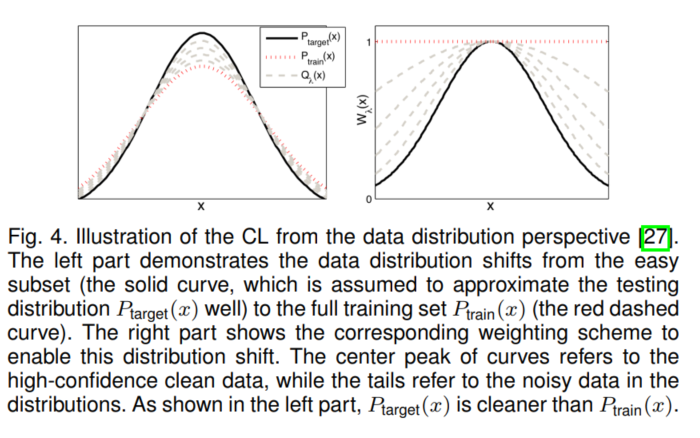

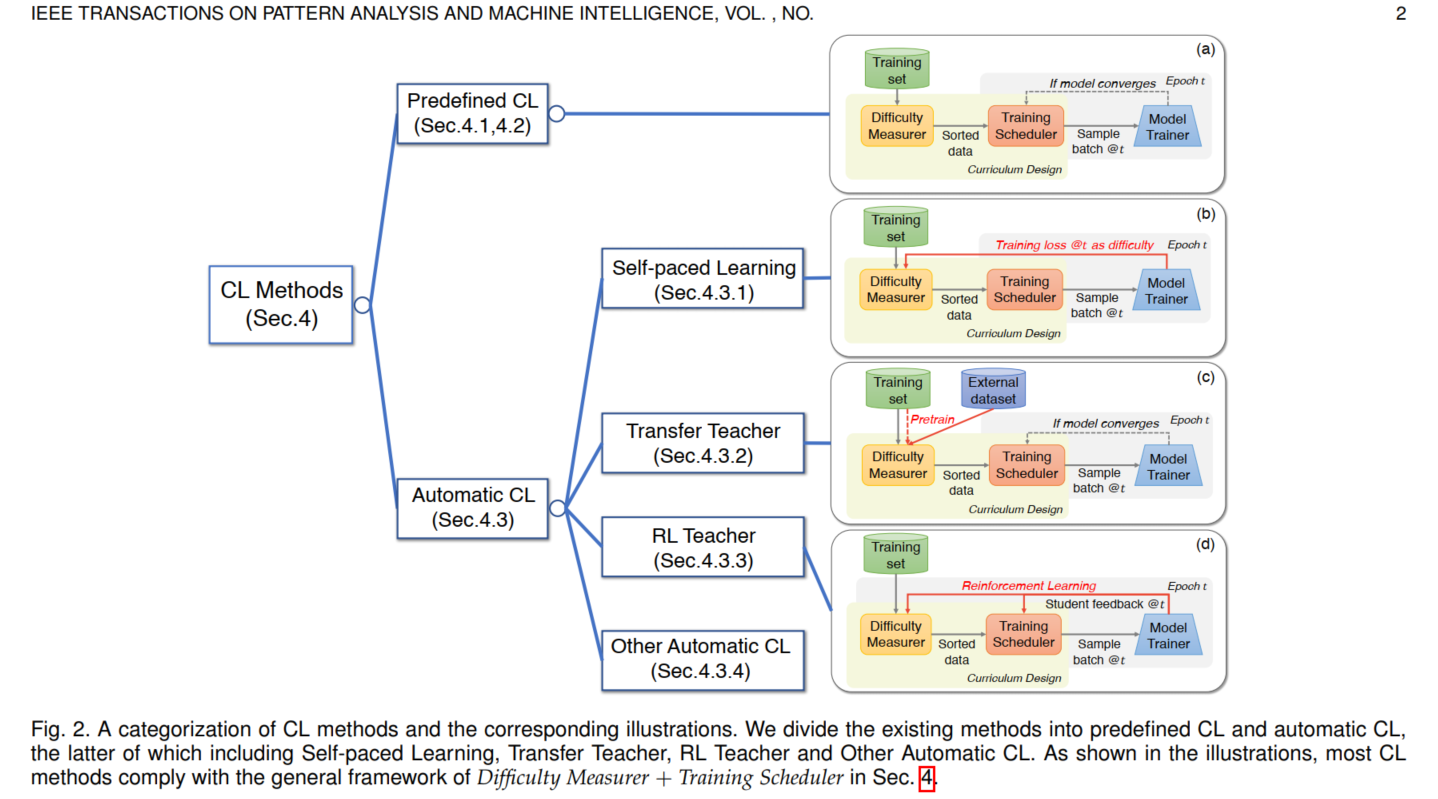
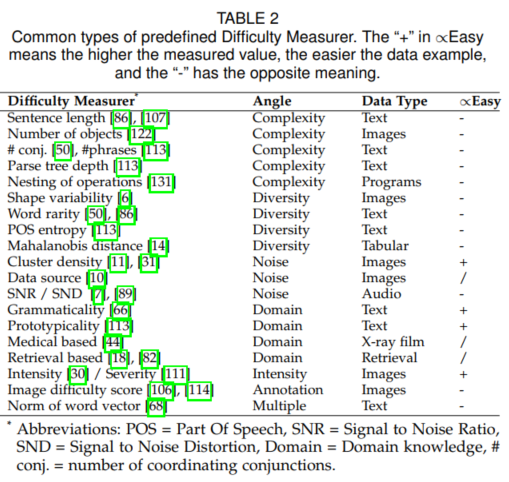


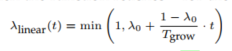











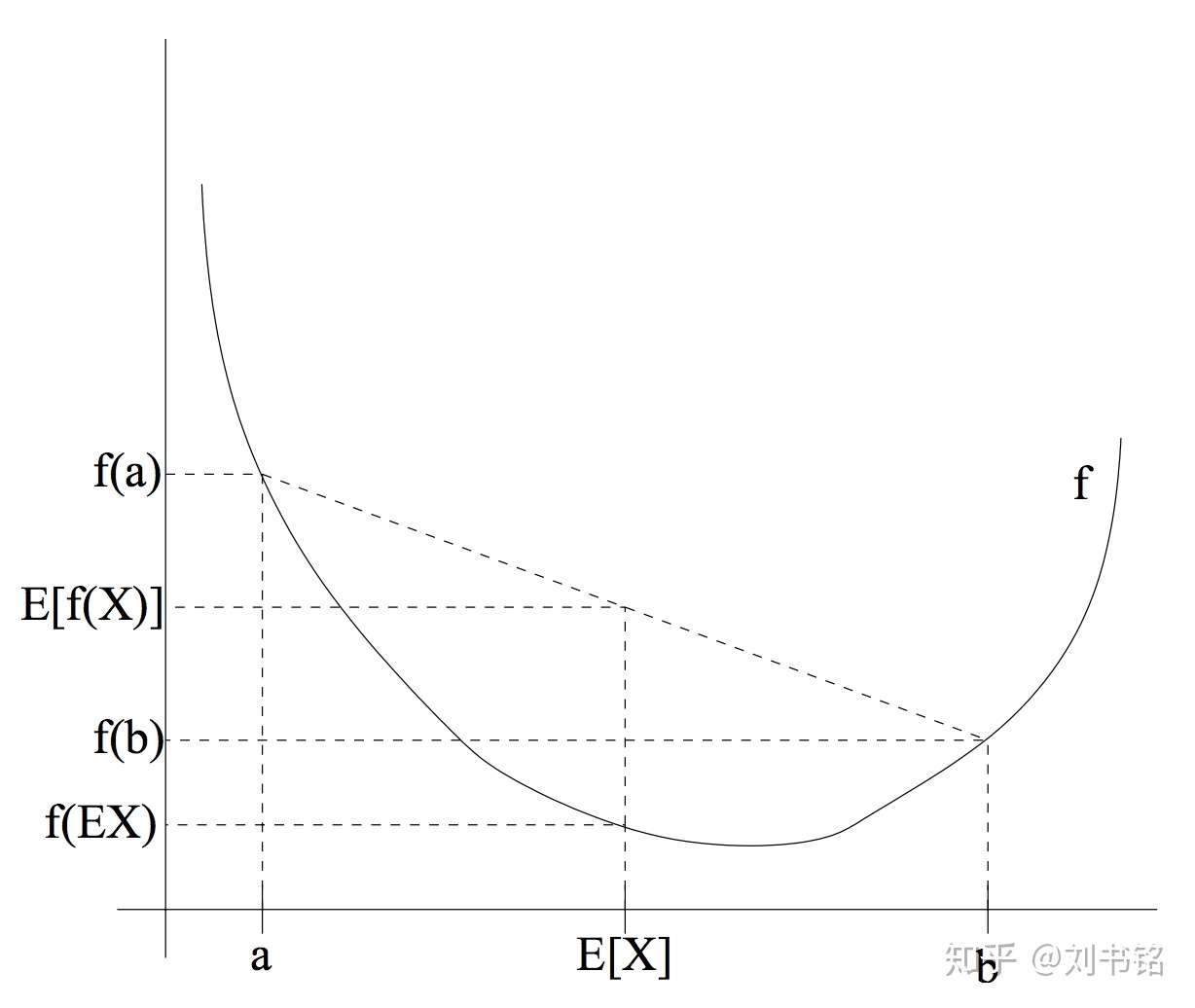 Fig 1. 一个凸函数以及E[(f(X))]和f[E(X)]的取值比较,这里X的分布是在a和b两点的均匀分布 (图片来自于Andrew Ng的讲义,见Reference & Acknowledgement)
Fig 1. 一个凸函数以及E[(f(X))]和f[E(X)]的取值比较,这里X的分布是在a和b两点的均匀分布 (图片来自于Andrew Ng的讲义,见Reference & Acknowledgement)