第七次周报
week 7 内容:
- louis philippe morency 《多模态机器学习》 50%
- 论文阅读:
- Collaborative Denoising Auto-Encoders for Top-N Recommender Systems
- Semantic Image Synthesis with Spatially-Adaptive Normalization
- DAGAN: Dual Attention GANs for Semantic Image Synthesis
Collaborative Denoising Auto-Encoders for Top-N Recommender Systems(WSDM 2016)
主要工作
top-N推荐任务具有较多应用场景。该文作者基于降噪自编码器(Denoising Autoencoder)提出了系统过滤推荐模型CDAE,用于完成基于用户偏好的top-N推荐任务。CDAE模型在特定情况下可对多种经典协同过滤模型做泛化,具有较强的可解释性。 ##### 模型
如上图所示,CDAE模型以用户-物品评价矩阵的行作为输入( 式模型),通过一层神经网络编码得到用户的隐藏表示,再通过一层神经网络还原用户的交互行为(隐式反馈)。与最简单的
模型不同,CDAE模型在编码得到隐藏表示时加入了对用户特征的考量,语义更丰富。为了使模型更具鲁棒性,CDAE模型对输入特征做了噪声处理(通过dropout或者加入高斯噪声实现)。
代码
1 | class CDAE(nn.Module): |

Semantic Image Synthesis with Spatially-Adaptive Normalization(CVPR 2019 Oral)
这篇文章提出了新的归一化层,从而让生成效果更好。由于相同语义像素的值趋同,分割图经过传统normalization往往会变为0((x-u)/v),因此输入不同的语义信息,BN等传统normalization会“wash away”语义信息。这篇文章通过提出SPADE结构来保留语义信息。

Network
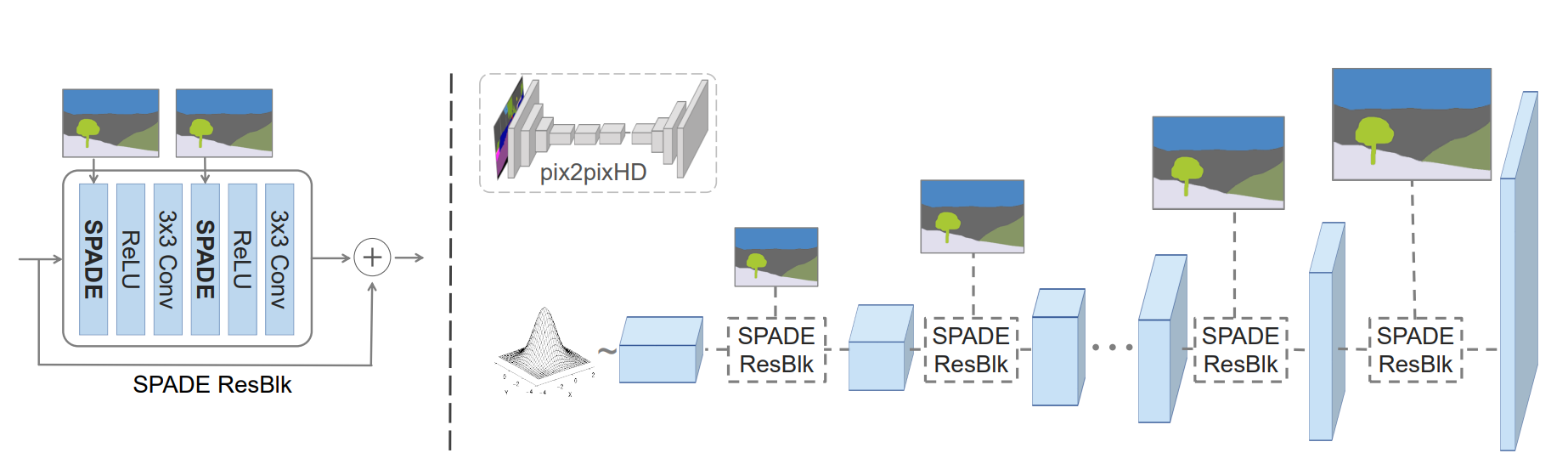
GauGan整体结构使用了上图所示SPADE ResBlk代替pix2pixHD中的resnetblock结构(SPADE替换了InstanceNorm)
Structure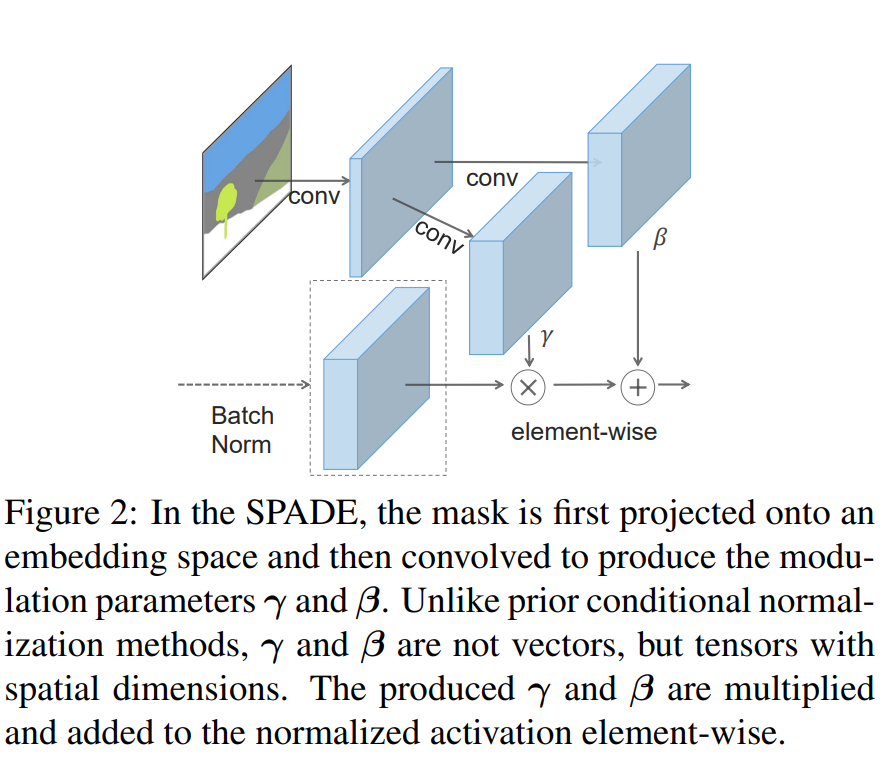

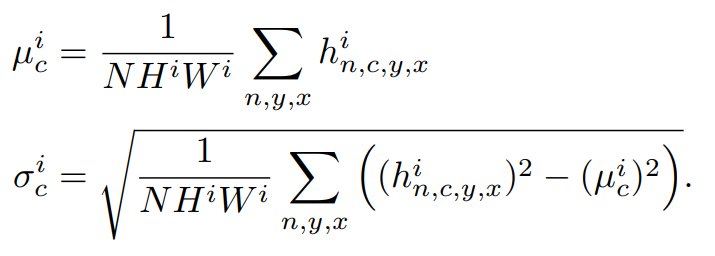
$\(和\) $代表着feature map上每个点的斜率和偏移量, 他们是通过两个卷积操作得到的;除此之外,剩下的就是按照每个通道做normalization。
DAGAN: Dual Attention GANs for Semantic Image Synthesis(ACM MM 2020)
Intro
这篇文章关心的问题在于通过语义分割图生成真实图像(phot-realistic images),该任务是conditional gan的一个延伸。现在相关的迁移工作都没有利用足够的语义信息限制生成过程,同时忽略了空间和通道的结构相关性(structure correlation),导致生成的照片大多缺乏细节同时生成痕迹明显(涂抹等)。
Network
这篇文章backbone network使用的是和GauGan相同的特征提取结构, 即backbone B。在Gaugan基础上引入空间注意力(SAM结构)和通道注意力(CAM结构)。
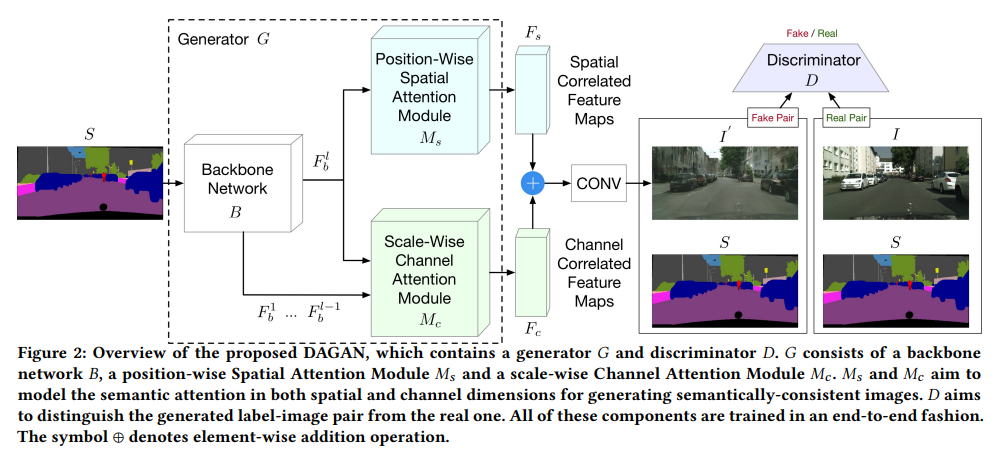
SAM将B的输出特征作为输入,输出空间相关特征图(语义模块在空间上的联系);CAM将B的每层特征作为输入,输出特征为通道相关特征图。通过元素加整合后输入卷积,得到fake image;对判别器D,它需要输入真实pair和假的pair,实现过程中将photo和语义分割图concat即可。
SAM:

backbone输出语义特征图首先分别进行max和avg pooling,将结果concate后输入卷积层和Sigmoid层,得到As是attention的weight,将As与Fb进行元素积,得到的Fs中相同label的pixel就有了联系(mutual gain), 这样生成的图片就可以有着语义上的持续性(一个object内的pixel应该是同样类别)
CAM:
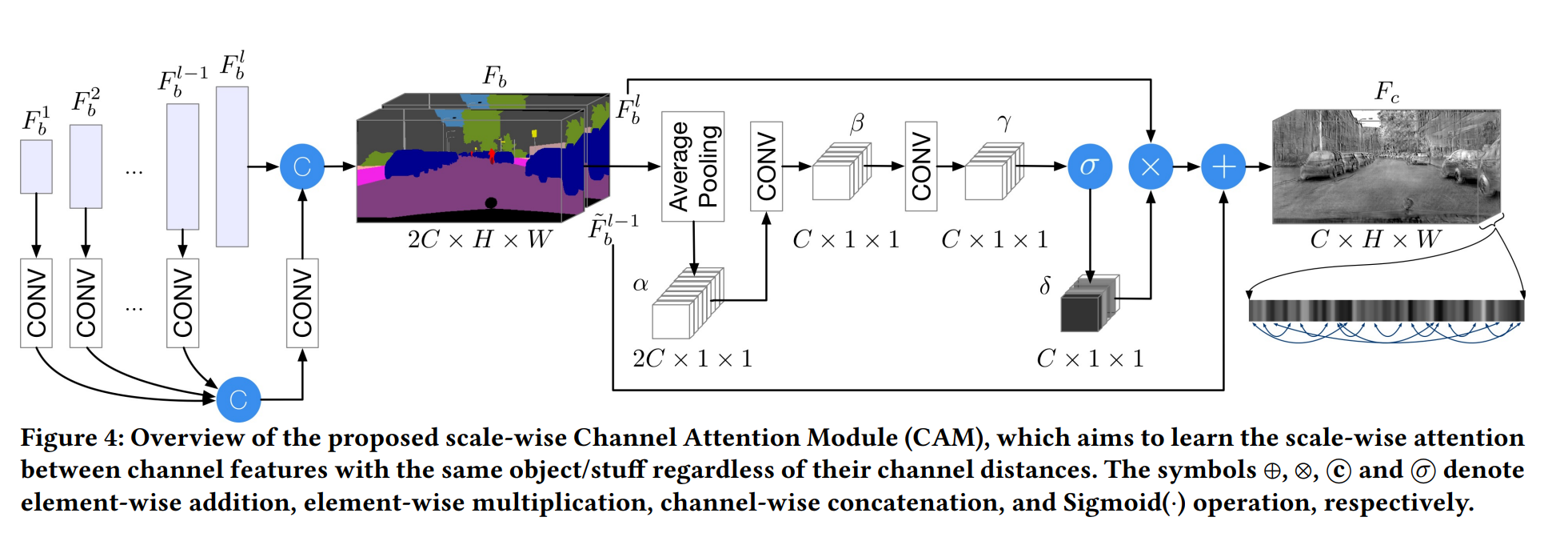
对于同样的objects,不同尺度的特征应该有联系。因此CAM将backbone中不同特征图做channel wised attention,有利于捕获这样的信息。实现中作者只用了上采样过程中的一个特征图(倒数第二个加conv),和输出做channel-wised concatnation(所以是2C x H x W)。Fb通过AdaptiveAvgPool再经过两个卷积层得到Cx1x1的
channel weights。最后的输出Fc通过两个部分元素加得到,即赋权后的\(F_b^l\)以及\(F_b^{l-1}\)
loss:
实现角度,gen loss
判别器:
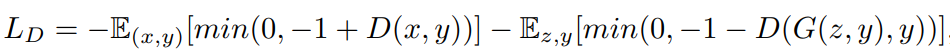
使用hinge loss衡量判别器效果,这样限制判别器去找最优的超平面。
生成器:
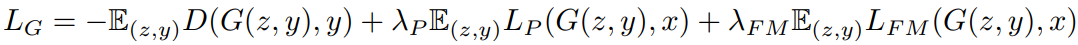
\(L_{FM}\)代表discriminator feature matching loss,它讲判别器的每层特征图抽出,确保real和fake特征图相近,借此优化G(discriminator部分使用detach(),确保更新G时D不动)
\(L_P\)为perceptual loss,它使用一个pretrain 的VGG进行特征提取,同样,确保fake和real的特征相近。(感觉这个是站在自然图像角度,确保两个pair)
整体看,实际上loss是分为了conditional adversarial loss,discriminator feature matching loss,perceptual loss
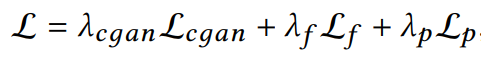
Variational Autoencoders for Collaborative Filtering(WWW 2018)
主要工作
该文作者把变分自编码器拓展应用于基于隐式反馈的协同过滤推荐任务,希望通过非线性概率模型克服线性因子模型的局限。该文提出了基于变分自编码器(Variational Autoencoder)的生成模型VAE_CF,并针对变分自编码器的正则参数和概率模型选取做了适当调整(使用了多项式分布),使其在当时推荐任务中取得SOTA结果。
模型
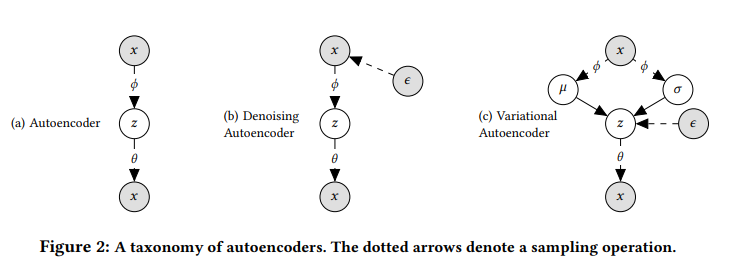
如上图所示,虚线代表了采样操作,a是传统AE,b是denoising AE, c代表论文提出的vae。该模型根据标准高斯分布抽取K维隐藏因子 ,然后根据非线性函数
生成用户
点击所有物品的概率分布
,最后根据多项式分布
重构用户点击历史(隐式反馈的用户-物品评价矩阵对应行)。
其目标函数(ELBO):

VAE_CF模型较标准的变分自编码器做了如下调整:
1、将正则参数调至0.2(低于常规值1),称其为部分正则化(partially regularized)
2、使用了多项式分布而非高斯分布。
- 多项式似然非常适合于隐式反馈数据的建模,并且更接近 rank loss;
- 无论数据的稀缺性如何,采用principled Bayesian方法都更加稳健。
使用SGD进行优化:
