第十一次周报
内容:
louis philippe morency 《多模态机器学习》 完成
kaggle fashion recommendation competition:
- 利用swing transformers提取了图片特征
论文阅读:
- sequential recommendation
- boosting相关
1 sequential recommendation
Session-based recommendations with recurrent neural networks(ICLR 2016)
背景:
GRU4rec是使用神经网络做序列推荐的经典基于会话的推荐方法(基本根据物品推荐,缺少用户侧信息),这篇文章出现前主要有基于物品的协同过滤和基于马尔可夫决策过程的方法。
- 基于物品的协同过滤,需要维护一张物品的相似度矩阵,当用户在一个session中点击了某一个物品时,基于相似度矩阵得到相似的物品推荐给用户。这种方法简单有效,并被广泛应用,但是这种方法只把用户上一次的点击考虑进去,而没有把前面多次的点击都考虑进去。
- 基于马尔可夫决策过程(MDP)的推荐方法,其主要学习的是状态转移概率,即点击了物品A之后,下一次点击的物品是B的概率,并基于这个状态转移概率进行推荐。这样的缺陷主要是随着物品的增加,建模所有的可能的点击序列是十分困难的
主要内容:
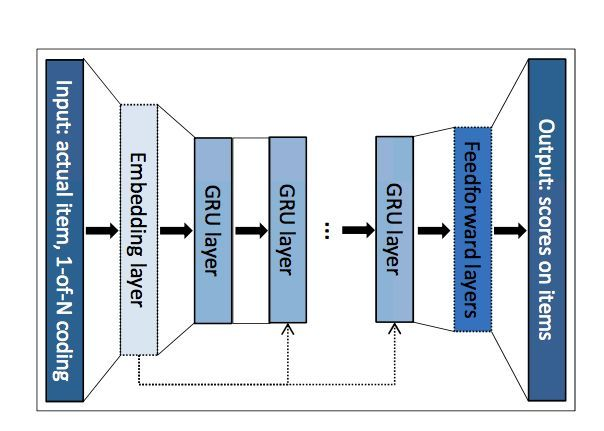
输入:对于一个Session中的点击序列\(x=[x_1,x_2,x_3...x_{r-1},x_r]\),依次将\(x_1,x_2,x_3...x_{r-1},x_r\)输入到模型中。
模型:序列中的每一个物品xt被转换为one-hot,随后转换成其对应的embedding,经过N层GRU单元后,经过一个全联接层得到下一次每个物品被点击的概率。
loss:
- bpr:\({\cal L}_{s}=-\frac{1}{N_{S}}\cdot\sum_{j=1}^{N_{S}}{\sigma}\left(\hat{r}_{s,i}\,-\,\hat{r}_{s,j}\right)\)。经典bpr让正样本和负样本之间得分差尽可能大。
- top1:\({\cal L}_{s}=\frac{1}{N_{S}}\cdot\sum_{j=1}^{N_{S}}{\sigma}\left(\hat{r}_{s,j}\,-\,\hat{r}_{s,i}\right)\,+\,\sigma\,\left(\hat{r}_{s,j}^{2}\right)\)第一项让正负样本之间差尽可能大(与bpr稍微有区别),第二项对负样本添加了正则项。
trick:
parallel:为了更好的并行计算,论文采用了 mini-batch 的处理,即把不同的session拼接起来(看纵向)
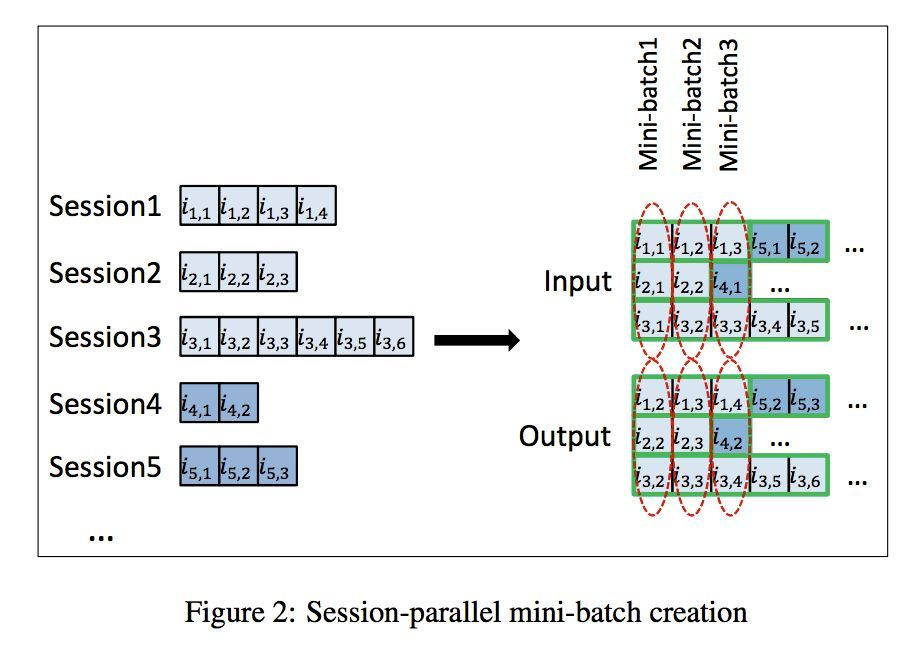
sampling on output:物品数量如果过多的话,模型输出的维度过多,计算量会十分庞大,因此在实践中一般采取负采样的方法。论文采用了取巧的方法来减少采样需要的计算量,即选取了同一个batch 中其他 sequence 下一个点击的 item作为负样本,用这些正负样本来训练整个神经网络。
Recurrent Neural Networks with Top-k Gains for Session-based Recommendations(CIKM 2018)
背景:
这篇文章从采样和损失函数角度对GRU4rec进行了优化,即很多序列推荐论文中的GRU4rec+对比算法。
主要内容
采样

在GRU4rec基础上,除了batch sampling(从batch中快速得到负样本),作者引入了额外的负样本(所有batch共享的)。
loss
cross-entropy:
当存在一个
时,
趋近于
,
未定义,造成结果不稳定。针对这个问题论文提出了2种代替
的计算方式:
,其中
。
- 去掉\(r_i\)对应的log,降低其为0情况
ranking losses:
- TOP1
- BPR [L_{bpr} =- _{j=1}^{N_s} log((r_i - r_j))](https://math.jianshu.com/math?formula=L_%7Bbpr%7D%20%3D-%20%5Cfrac%7B1%7D%7BN_s%7D%20%5Csum_%7Bj%3D1%7D%5E%7BN_s%7D%20log(%5Csigma%20(r_i%20-%20r_j))
其中,
为负样本量大小,
为 item
k的分数,i代表正样本,j代表负样本。这两种损失函数主要缺点是会发生梯度消失的现象,如当
时,
和
都会趋近于
[ = - {j=1}^{N_s} (r{j} - r_{i}) (1- (r_{j} - r_{i}))](https://math.jianshu.com/math?formula=%5Cfrac%7B%5Cpartial%20L_%7Btop1%7D%7D%7B%5Cpartial%20r_i%7D%20%3D%20-%20%5Cfrac%20%7B1%7D%7BN_s%7D%20%5Csum_%7Bj%3D1%7D%5E%7BN_s%7D%20%5Csigma%20(r_%7Bj%7D%20-%20r_%7Bi%7D)%20(1-%20%5Csigma%20(r_%7Bj%7D%20-%20r_%7Bi%7D))
[ =- _{j=1}^{N_s} (1-(r_i - r_j))](https://math.jianshu.com/math?formula=%5Cfrac%7B%5Cpartial%20L_%7Bbpr%7D%7D%7B%5Cpartial%20r_i%7D%20%3D-%20%5Cfrac%7B1%7D%7BN_s%7D%20%5Csum_%7Bj%3D1%7D%5E%7BN_s%7D%20(1-%5Csigma%20(r_i%20-%20r_j))
- TOP1
ranking-max losses:
为了克服梯度消失的情况,作者提出了ranking-max的loss框架:
\({\cal L}_{\mathrm{pairwise-max}}\left(r_{i},\{r_{j}\}_{j=1}^{N_{S}}\right)={\cal L}_{\mathrm{pairwise}}(r_{i},{\bf m}_{\mathrm{ax}}\,r_{j})\)
- TOP1-max [L_{top1-max} = {j=1}^{N_s} s_j((r{j} - r_{i}) + (r_{j} ^2))](https://math.jianshu.com/math?formula=L_%7Btop1-max%7D%20%3D%20%5Csum_%7Bj%3D1%7D%5E%7BN_s%7D%20s_j(%5Csigma%20(r_%7Bj%7D%20-%20r_%7Bi%7D)%20%2B%20%5Csigma%20(r_%7Bj%7D%20%5E2))
[ = - {j=1}^{N_s}s_j (r{j} - r_{i}) (1- (r_{j} - r_{i}))](https://math.jianshu.com/math?formula=%5Cfrac%7B%5Cpartial%20L_%7Btop1-max%7D%7D%7B%5Cpartial%20r_i%7D%20%3D%20-%20%5Csum_%7Bj%3D1%7D%5E%7BN_s%7Ds_j%20%5Csigma%20(r_%7Bj%7D%20-%20r_%7Bi%7D)%20(1-%20%5Csigma%20(r_%7Bj%7D%20-%20r_%7Bi%7D)) 其中 maxsoft score 相当于权重(对每个负样本加权重,sj和为1),当
较小时,
也会较小(趋近于 0),样本
类似于被忽略,所以不会减少整体的梯度。
- BPR-max
\({\frac{\partial{\cal L}_{\mathrm{bpr}-\mathrm{max}}}{\partial r_{k}}}=s_{k}-{\frac{s_{k}\sigma^{2}(r_{i}-r_{k})}{\sum_{j=1}^{N_{S}}s_{j}\sigma(r_{i}-r_{j})}}\) 这里的梯度信息可以看做是单个梯度的加权平均值,
相当于权重。当
较小时,权重分布较为均匀,实际得分高的将会得到更多关注;当
TOP1-max 和 BPR-max 的梯度信息均和 softmax score 成比例,这意味着只有 score 较大的 item 会被更新,这样的好处在于模型训练过程中会一直推动 target 往排序列表的顶部前进,而常规的 TOP1 和 BPR 在 target 快接近顶部的时候,平均梯度信息更小了,更新几乎停滞,这样很难将 target 推至顶部。
- BPR-max with score regularization 受 TOP1 添加正则项的启发,对 BPR 添加正则项,同样能提高模型的表现。
其中,
为正则项参数。
1 | # 传统bpr |
基于注意力的方法& transformer-based methods:
SASRec: Self-Attentive Sequential Recommendation(ICDM 2018)
背景:
之前的序列建模方法:
- 基于MC的方法,通过一个简单的假设,进行信息的状态转移。在高稀疏数据下表现好,但在更复杂的场景中很难捕捉到有用的信息,文章实验也证明了这点;
- 基于RNN的方法有很强的表达能力,但是训练需要大量的数据,在密集型数据集下表现得更好,且因为每一个隐藏状态都必须依赖于前一个,运行效率较低;
注意力机制背后的思想是连续的输出都依赖于某个输入的“相关”部分,而模型应该连续地关注这些输入,在推荐领域,AFM、DIN模型已经得到了很好的应用,详见基于注意力的方法
主要内容:
- Postional embedding(PE):即transformer中的位置编码表示先后顺序。对于稀疏数据集可不加pe,因为用户没有太多的记录,因此购买顺序没有太大关系。
Self-Attention层
原transformer中self-attention(K=V):
[公式] 在本文中对应的是
此时K!=V,作者认为这样可以让模型更加灵活,比如对于<query q, key k>以及< key k, query q>就可以有不同的表示。
此外, 考虑到不同维度隐藏特征的非线性交互,本文与Transformer一样,在self-attention之后,采取两层的前馈网络:
stack transformer
一般而言叠加多个自注意力机制层能够学习更复杂的特征转换,但会存在一些问题:
模型更容易过拟合;
训练过程不稳定(梯度消失问题等);
模型需要学习更多的参数以及需要更长的时间训练;
因此,作者在自注意力机制层和前馈网络「加入残差连接、Layer Normalization、Dropout」来抑制模型的过拟合。(依旧按照transformer设置)
[公式] prediction(与训练好的item embeddings做点积,实际实现时用的都是同一个item embedding)
[公式] 作者还尝试通过引入user embedding,但是没有提高性能:
[公式]
对比BST(KDD2019)
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba这篇论文同样是使用了transformer应用在序列推荐中,但是BST面向排序阶段(SAS面向召回阶段),把序列推荐看成一个CTR任务, 引入了(other features: 用户基本特征、物品基本特征、上下文信息等),模型结构:
FDSA: Feature-level Deeper Self-Attention Network for Sequential Recommendation(IJCAI 2019)
背景:
SAS只考虑物品之间的顺序模式,而忽略了有助于捕获用户细粒度兴趣偏好的特征之间的顺序模式。 事实上,我们的日常item-item关系是十分重要的。例如,用户在买了衣服之后更可能买鞋子,显示出了下一个产品的类别与当前产品的类别具有高度的相关性。
作者将用户对结构化属性(例如类别)不断变化的需求称为显式的特征转换。此外,物品还可能包含一些非结构化属性,如描述文本或图像,这些属性表示物品的更多细节。因此,作者希望从这些非结构化属性中挖掘用户潜在的特征级别模式,称之为隐式特征转换。
因此FDSA通过对物品序列和特征序列分别应用不同的自注意块,对显式和隐式特征转换进行建模。为了获得隐式的特征转换,增加了一种vanilla注意机制,以帮助基于特征的自注意力块自适应地从各种物品属性中选择重要的特征。
主要工作:

FDSA由5部分组成,Embedding layer, Vanilla attention layer, Item-based self-attention block, Feature-based self-attention block, 以及FFN。
首先将稀疏的物品以及物品的离散属性映射到低维稠密向量(embedding)。对物品的文本属性,利用主题模型提取关键词,然后利用word2vec获得关键词的文本向量表示。
物品的特征通常是异构的,利用传统注意力从物品的各种特征中选择重要的特征。
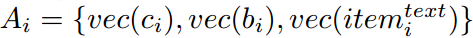
在这里插入图片描述 $ vec(c_i), vec(b_i) \(为物品类别和品牌的稠密向量表示,\) vec(item_i^{text}) $ 表示文本i的文本特征表示。
注意力得分为:
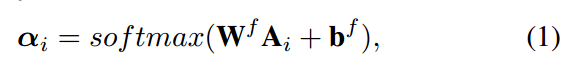
物品级和序列级特征分别输入transformer,最后拼接在一起得到最后预测结果。
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer(CIKM 2019)
将Bert应用到推荐,完全相同的模型(没有next sentence prediction,因为无意义)。
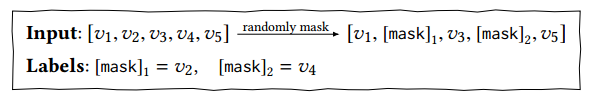
S3-Rec: Self-Supervised Learning for Sequential Recommendation with MIM(CIKM2020)
背景:
现有的神经网络模型利用预测损失来学习模型参数或者嵌入表征,但是这样的训练受限于数据稀疏问题。
各类数据之间的关系没有被充分挖掘出来——上下文数据和序列数据之间的关联或融合一直不太好捕捉并用于序列推荐(pretrain对于提高性能有影响,说明直接单一目标函数训练是不够的)。
主要内容:
S3-rec利用原有数据的相关性来构建自监督信号,并通过预训练方法来增强数据表示,以改善序列推荐。它利用互信息最大化(MIM)原理来学习属性,物品,子序列和序列之间的相关性。
互信息最大化
互信息:信息论中,互信息是不确定性减少的度量。让互信息最大化,就是让不确定性尽可能降低,充分挖掘数据之间的关系。


互信息(KL(p(x,y)||p(x)p(y)))一般通过NCE实现(NCE来自NLP,是互信息的下限https://arxiv.org/pdf/1807.03748.pdf):
https://zhuanlan.zhihu.com/p/334772391
https://zhuanlan.zhihu.com/p/413681189

模型

Modeling Item-Attribute Correlation:最大化物品和属性间的互信息。

对于每个物品,属性都提供其细粒度信息。 因此通过对物品-属性相关性进行建模来融合物品和属性级别的信息。以这种方式,期望将有用的属性信息融入到物品表示中。
用双线性模型建模属性向量之间相关性:

img NCEloss:

img Modeling Sequence-Item Correlation

img 和bert4rec, 一样在每个训练步骤中,随机掩盖输入序列中的一部分物品(即,将它们替换为特殊标记“ [mask]”)。 然后,基于两个方向上的上下文从原始序列中预测被mask的物品。
对应loss(F代表mask位置预测的embedding):

img 
img Modeling Sequence-Attribute Correlation

img 融合序列上下文和物品属性信息(现有方法很少这样关联的):

img 
img Modeling Sequence-Segment Correlation

img 物品序列与单词序列之间的主要区别在于单个物品项目可能与周围环境没有高度关联。例如,用户仅仅因为某些产品就在购买中而购买了它们,严格的上下文信息并不是决定因素。因此作者还考虑了子序列(序列模式,不是考虑严格位置关系,考虑相对位置关系)。

img 
img
训练
模型训练包括预训练和微调两个阶段,预训练过程中利用上面的4个Loss即4个子任务通过无掩码的自注意力机制进行训练,得到高质量的物品表征和属性表征。
微调阶段再来使用pairwise loss训练:

2 BOOSTING
GB
梯度提升(Gradient Boost)核心思想是,用多个弱分类器(比如生成的子树)来构建一个强分类器(最终集成出来的树)。每一棵树(以回归树为例)学习的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。
GBT
梯度提升树(GBT)的一个核心思想是利用损失函数的负梯度在当前模型的值作为残差的近似值,本质上是对损失函数进行一阶泰勒展开,从而拟合一个回归树。
一阶泰勒:
对应损失函数展开:
其中对于平方或指数损失函数,就是通常意义上的残差。对于其他普通函数,残差是导数的近似值。用于回归模型时,是梯度提升回归树GBRT;梯度提升树用于分类模型时,是梯度提升决策树GBDT;二者的区别主要是损失函数不同。
XGBoost
算法
目标函数:
相比GBDT引入了正则项, 表示给定一颗树的叶节点数,决策树定义为
,
为某一样本,这里的
表示该样本所在的叶子结点,
为叶子结点权重
,所以得出
为每个样本的取值
(即预测值)。所以
表示每颗树叶节点上的输出分数的平方(相当于L2正则)
在通常的模型中针对这类目标函数可以使用梯度下降的方式进行优化,但注意到 表示的是一颗树,而非一个数值型的向量,所以不能使用梯度下降的方式去优化该目标函数。在此作者提出了使用 前向分步算法(additive manner)。
目标函数为:
其中第 i 个样本在第 t 颗树的预测值 ()等于样本 i 在前 t-1 棵树的预测值(
) 加当前第 t 颗树预测值(
) 公式表达为:
对于该函数的优化,在 XGBoost 中使用了泰勒展开式,与 GDBT 不同的是 XGBoost 使用了泰勒二次展开式。
使
这里是针对 的求导,所以可以将
部分看成常数去掉。
得出简化后的损失函数:
如果确定了树的结构,为了使目标函数最小,可以令其导数为0,解得每个叶节点\(j\)的最优预测分数为:
将 代入简化后的目标函数得到最小损失为:
另 则有:
直观上看,判断一棵树的好坏,就可以根据上面的\(L^{(t)}\)进行判断,loss越小(注意loss中的负号),代表树的结构越好。
作者在划分时用了贪心算法。假设在某节点分裂了左 ,右节点
且满足 如果确定了树的结构(即q(x)确定),为了使目标函数最小,可以令其导数为0,解得每个叶节点的最有预测分数为:
,
那么分裂后增益 可以表示为:
该值越大,说明分裂后能使目标函数减少越多,就越好。此方法被用于 XGBoost 判断最优特征以及最优切分点。
Shrinkage & 列降采样
- Shrinkage 策略(权重衰减,类似 LSTM)。比如把整个训练过程看作一个时间序列,离当前树时间点越靠前的权重对当前权重的累加影响越小,这个衰减就是论文里的参数
控制的。(时间做平滑)
- 特征降采样的方法来避免过拟合,只是这里的降采样使用的是列降采样(与随机森林做法一样每次的输入特征不是全部特征,不仅能降低过拟合,还能减少计算),它的另外一个好处是可以方便加速并行化
分裂点
每个树生成的问题都要考虑到两个问题是:1)按照哪个维度 / 顺序组合切 2)如何判断*最佳切分点*。
贪心算法
从树的根节点开始,对每个叶节点枚举所有的可用特征。此处文中指出:对该节下的数据需令其按特征值进行排序,这样做可以使计算分裂收益值更加高效,*分裂收益值* 计算如下:
[公式] 然后选择该轮最大收益值作为*最佳分裂点* ,使在该节点行分裂出左右两个新的叶节点,并重新分配新节点上的样本。至此一个循环结束,继续按同样流程递归迭代直至满足条件停止。在特征维度较大的时候,内存会不够。
近似值
作者提出将连续特征变量按照特征值分布进行分桶操作的方法,这样只需要计算每个桶中的统计信息就可以求出最佳分裂点的最佳分裂收益值。
在确定分裂点时作者提出了两种方法:Global、Local。
Global 表示在生成树之前进行候选切分点(candidate splits)的计算,且在整个计算过程中只做一次操作。在以后的节点划分时都使用已经提前计算好的候选切分点;Local 则是在每次节点划分时才进行候选切分点的计算。Global 适合在取大量切分点下使用; Local 更适用于深度较大的树结构。
LightGBM
https://zhuanlan.zhihu.com/p/99069186
对xgboost的优化:
基于Histogram的决策树算法。
直方图方式进行分桶, 将特征离散化(与xgboost一样仅考虑非零特征)。
CSDN图标 Histogram(直方图)做差加速。一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到,在速度上可以提升一倍。
单边梯度采样 Gradient-based One-Side Sampling(GOSS):使用GOSS可以减少大量只具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有高梯度的数据就可以了,相比XGBoost遍历所有特征值节省了不少时间和空间上的开销。
GOSS排除大部分小梯度的样本,仅用剩下的样本计算信息增益,它是一种在减少数据量和保证精度上平衡的算法。
互斥特征捆绑 Exclusive Feature Bundling(EFB):使用EFB可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的。
带深度限制的Leaf-wise的叶子生长策略:大多数GBDT工具使用低效的按层生长 (level-wise) 的决策树生长策略,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销。实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。LightGBM使用了带有深度限制的按叶子生长 (leaf-wise) 算法:
该策略每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,Leaf-wise的优点是:在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度;Leaf-wise的缺点是:可能会长出比较深的决策树,产生过拟合。因此LightGBM会在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
直接支持类别特征(Categorical Feature)
支持高效并行
Cache命中率优化
