蘑菇书笔记
绪论
基本问题
强化学习的基本结构是什么?
智能体与环境的交互。(当智能体在环境中得到当前时刻的状态后,其会基于此状态 输出一个动作,这个动作会在环境中被执行并输出下一个状态和当前的这个动作得到的奖励。智能体在环 境里存在的目标是最大化期望累积奖励。)
强化学习相对于监督学习为什么训练过程会更加困难?(与监督学习的不同)
- 强化学习处理的大多是序列数据,其很难像监督学习的样本一样满足独立同分布条件。
- 强化学习有奖励的延迟,即智能体的动作作用在环境中时,环境对于智能体状态的奖励存在延迟, 使得反馈不实时
- 监督学习有正确的标签,模型可以通过标签修正自己的预测来更新模型,而强化学习相当于一个 “试错”的过程,其完全根据环境的“反馈”更新对自己最有利的动作。
强化学习的基本特征有哪些?
- 有试错探索过程
- 会从环境中获得延迟奖励
- 数据都是时间关联的
- 智能体的动作会影响它从环境中得到的反馈
近几年强化学习发展迅速的原因有哪些?
算力的提升、深度强化学习端到端训练
状态和观测有什么关系?
状态是对环境的完整描述,不会隐藏环境信息。观测是对状态的部分描述,可能会遗漏一些信息。
一个强化学习智能体由什么组成?
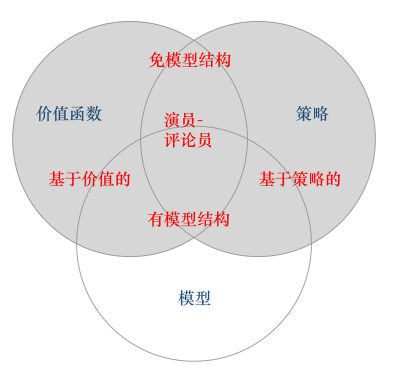
策略函数、价值函数、模型(智能体对当前环境状态的理解)
根据强化学习智能体的不同,我们可以将其分为哪几类?
基于价值的智能体、基于策略的智能体、演员-评论员
基于策略迭代和基于价值迭代的强化学习方法有什么区别?
基于策略迭代的强化学习方法,智能体会制定一套动作策略,即确定在给定状态下需要采取何种 动作,并根据该策略进行操作。强化学习算法直接对策略进行优化,使得制定的策略能够获得最大的奖励; 基于价值迭代的强化学习方法,智能体不需要制定显式的策略,它维护一个价值表格或价值函数,并通过 这个价值表格或价值函数来选取价值最大的动作。
基于价值迭代的方法只能应用在离散的环境下,例如围棋或某些游戏领域,对于行为集合规模庞 大或是动作连续的场景,如机器人控制领域,其很难学习到较好的结果(此时基于策略迭代的方法能够根 据设定的策略来选择连续的动作)。
面试问题
友善的面试官: 看来你对于强化学习还是有一定了解的呀,那么可以用一句话谈一下你对于强化学习的认识吗?
强化学习包含环境、动作和奖励 3 部分,其本质是智能体通过与环境的交互,使其做出的动作对应的决策得到的总奖励最大,或者说是期望最大。
友善的面试官: 请问,你认为强化学习、监督学习和无监督学习三者有什么区别呢?
1. 强化学习和无监督学习是不需要有标签样本的,而监督学习需要许多有标签样本来进行模型的构建和训练。
2. 对于强化学习与无监督学习,无监督学习直接基于给定的数据进行建模,寻找数据或特征中隐藏的结构,一般对应聚类问题;强化学习需要通过延迟奖励学习策略来得到模型与目标的距离,这个 距离可以通过奖励函数进行定量判断,这里我们可以将奖励函数视为正确目标的一个稀疏、延迟形式。
3. 强化学习处理的多是序列数据,样本之间通常具有强相关性,但其很难像监督学习的样本一样满足独 立同分布条件。友善的面试官: 根据你的理解,你认为强化学习的使用场景有哪些呢?
“多序列决策问题”,或者说是对应的模型未知,需要通过学习逐渐逼近真实模型的 问题。并且当前的动作会影响环境的状态,即具有马尔可夫性的问题。同时应满足所有状态是可重复到达 的条件,即满足可学习条件。
友善的面试官: 请问强化学习中所谓的损失函数与深度学习中的损失函数有什么区别呢?
深度学习中的损失函数的目的是使预测值和真实值之间的差距尽可能小,而强化学习中的损失函数的目的是使总奖励的期望尽可能大。
友善的面试官: 你了解有模型和免模型吗?两者具体有什么区别呢?
是否需要对真实的环境进行建模,免模型方法不需要对环境进行建模,直 接与真实环境进行交互即可,所以其通常需要较多的数据或者采样工作来优化策略,这也使其对于真实环 境具有更好的泛化性能;而有模型方法需要对环境进行建模,同时在真实环境与虚拟环境中进行学习,如 果建模的环境与真实环境的差异较大,那么会限制其泛化性能。